Gebaut für Analysten, die Plumbing hassen.
Harbinger Explorer ist ein KI-Daten-Workspace, der API-Docs und Dateien in abfragbare Tabellen verwandelt — im Browser, in Minuten, mit eingebauter Governance.

Marc Cherier
Gründer & Lead Engineer
Databricks Certified Professional · 2x WEF Hackathon Gewinner
LinkedInWer steckt dahinter
Nach Jahren des Aufbaus von Datenpipelines und Integrationsschichten für Unternehmenskunden war die Frustration immer dieselbe: Wochen an Setup vor der ersten nützlichen Abfrage. Hunderte Zeilen Boilerplate, nur um eine API anzusprechen und Daten in eine Tabelle zu laden.
Jede neue API bedeutete denselben Zyklus: Docs lesen, Auth-Logik schreiben, Pagination handhaben, die Antwort normalisieren, in ein Warehouse laden. Für eine einzelne Quelle. Multipliziert man das mit zehn, hat man ein Quartal nur mit Plumbing verloren.
Harbinger Explorer existiert, um diese Lücke zu schließen — um Analysten und kleinen Teams denselben Katalog, dieselbe Governance und Explorationskraft zu geben, die früher ein dediziertes Datenplattform-Team und ein sechsstelliges Budget erforderten. Ein Tool, im Browser, mit KI, die die langweiligen Teile für Sie erledigt.
Datenarbeit besteht immer noch zu 80 % aus Plumbing.
Teams verbringen mehr Zeit mit Verbinden, Laden und Bereinigen als mit tatsächlicher Analyse. Wir haben Harbinger Explorer gebaut, weil wir diese Probleme selbst erlebt haben.
“Eine neue API anbinden dauert eine Woche”
Docs lesen, Auth-Logik schreiben, paginieren, normalisieren, in ein Warehouse laden. Für jede einzelne Quelle.
“Ad-hoc-Analysen erfordern ein volles Python-Setup”
Man will nur eine Tabelle prüfen, aber zuerst: venv, pip install, Jupyter, Credentials, Connection-Strings.
“Governance ist immer ein Nachgedanke”
PII rutscht unbemerkt durch Pipelines. Bis jemand es meldet, steckt es bereits in drei Dashboards.
“Datenkataloge sind teuer und komplex”
Enterprise-Tools kosten sechsstellig und brauchen ein dediziertes Team. Kleine und mittlere Teams bekommen nichts.
Schnelle, präzise Einblicke — ohne den Overhead.
Keine Pipelines zu warten, kein Warehouse zu provisionieren, keine Python-Umgebung zu konfigurieren. Nur Ihr Browser und Ihre Daten.
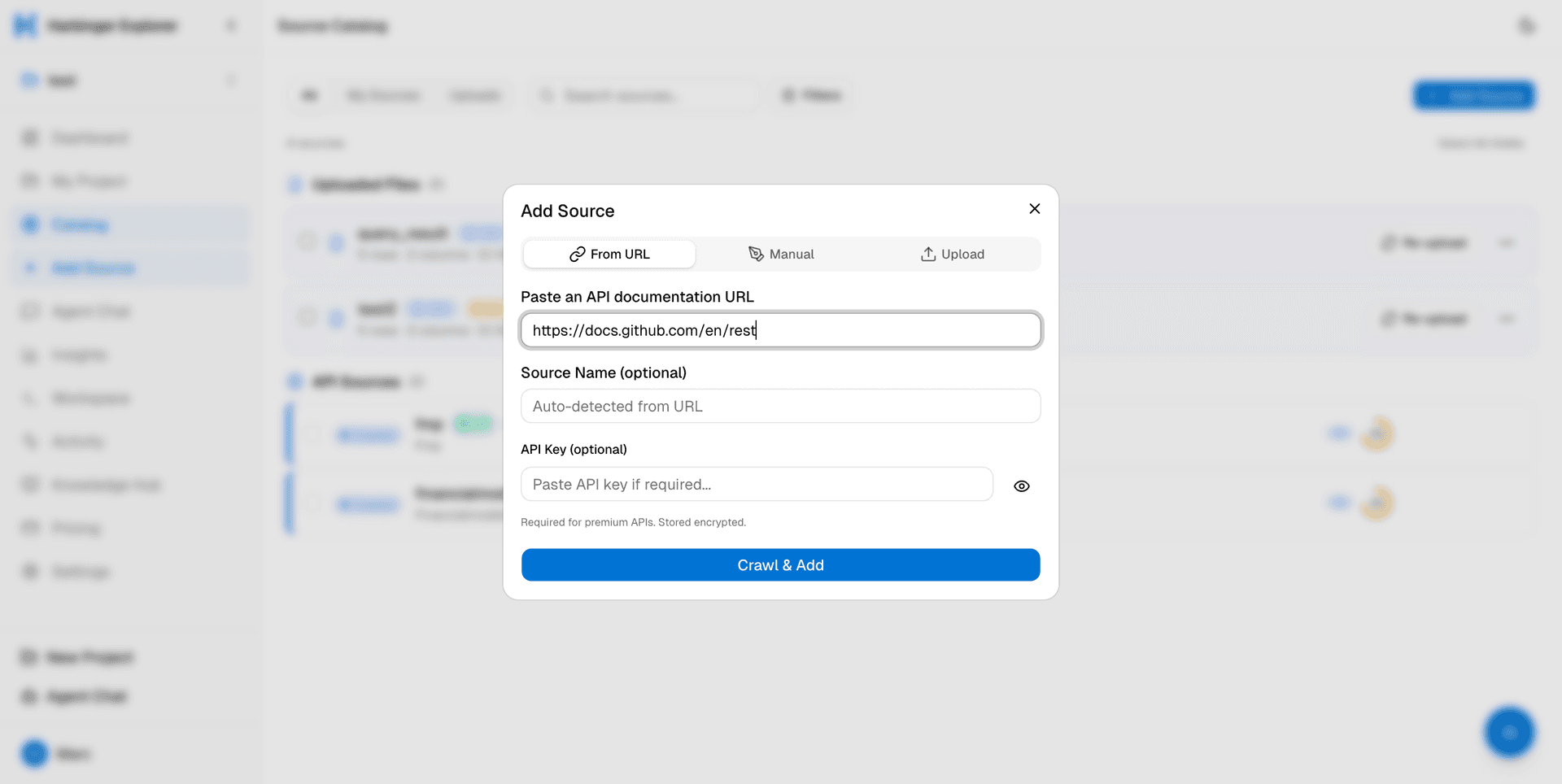
Einfach reinwerfen
API-Docs-URL einfügen oder CSV, Excel, JSON, Parquet per Drag & Drop ablegen. Der Agent liest Dokumentation, entdeckt Endpunkte, mappt Schemas und baut Ihren Katalog automatisch auf.
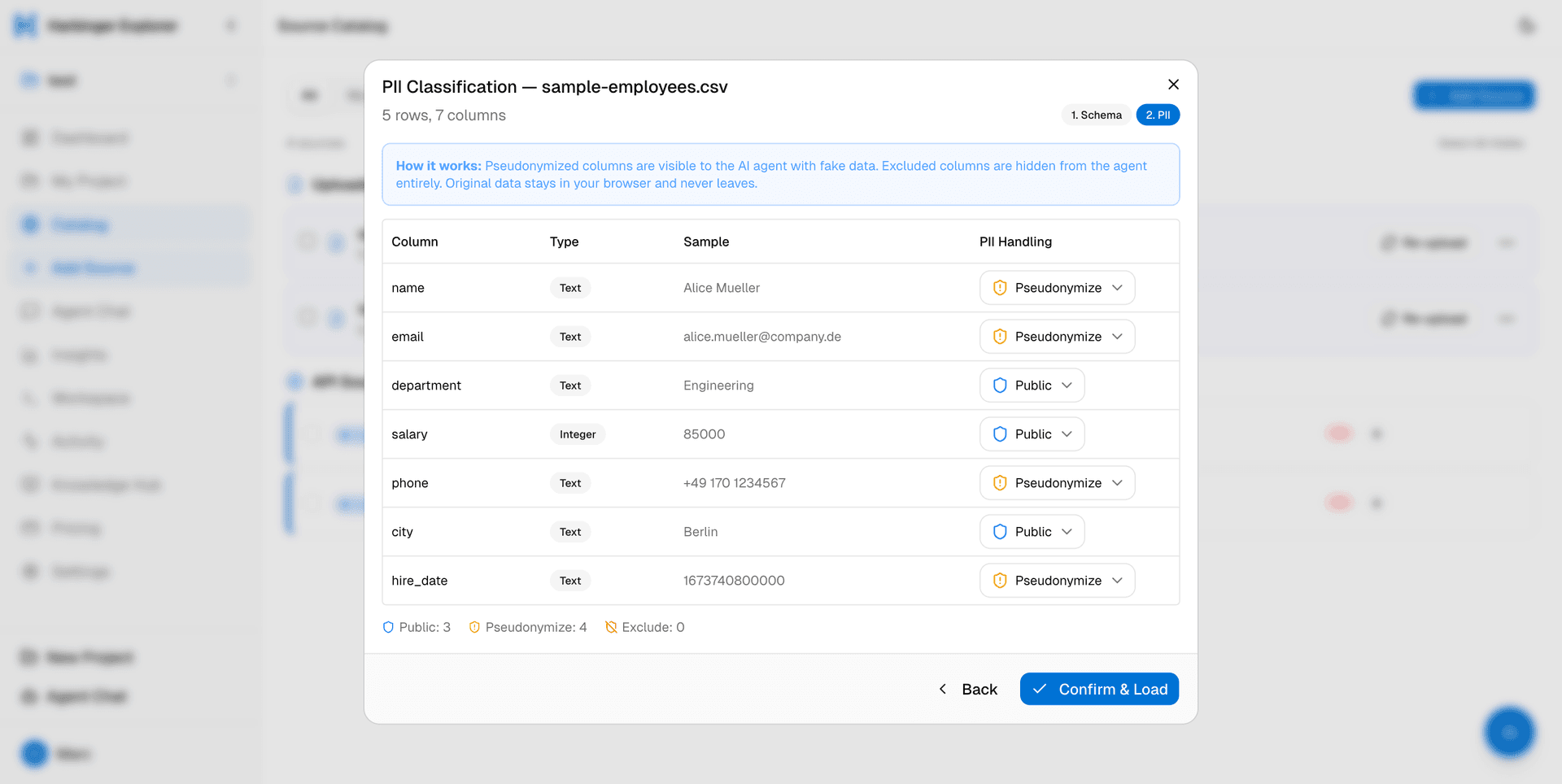
Governed ab Zeile eins
Jede Spalte wird beim Laden sofort auf PII gescannt — E-Mails, Telefonnummern, IDs werden sofort markiert. Sie entscheiden pro Spalte: erlauben, pseudonymisieren oder ausschließen. Der Agent sieht niemals Rohwerte.
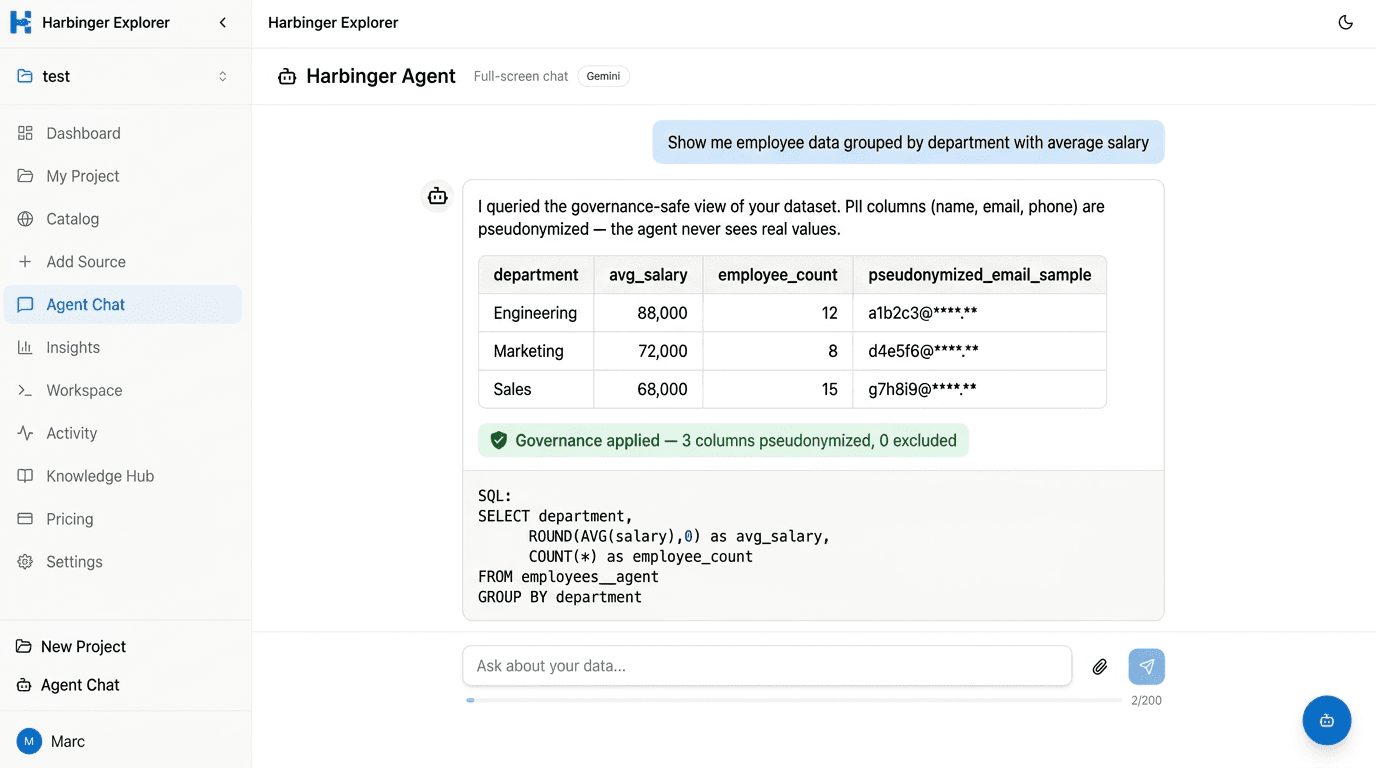
Fragen oder abfragen
Chatten Sie mit der KI in natürlicher Sprache — sie fragt Ihre geschützten Daten ab, zeigt Ergebnisse in einer Tabelle und macht das SQL dahinter sichtbar. Oder öffnen Sie den vollen SQL-Workspace für manuelle Kontrolle mit Autovervollständigung und Joins in Sekundenbruchteilen.
Was jede Entscheidung antreibt
Drei Prinzipien, die bestimmen, wie wir bauen, was wir ausliefern und wie wir Ihre Daten behandeln.
Sicher
EU-gehostete Infrastruktur, AES-256-Verschlüsselung im Ruhezustand und automatische PII-Erkennung auf jeder Spalte. Ihre Daten verlassen Europa nie, und Governance wird durchgesetzt, bevor irgendetwas abfragbar ist.
Transparent
Vollständiger Audit-Trail bei jeder Abfrage, jedem Export, jeder Governance-Entscheidung. Sie sehen genau, worauf der KI-Agent zugreift, was er maskiert und warum. Keine Black Boxes.
Innovativ
Browser-natives SQL, ein KI-Agent der API-Docs für Sie liest, und ein Katalog der Lineage über Quellen hinweg verfolgt. Gebaut mit dem Stack von morgen, nutzbar heute.
Lassen Sie uns reden.
Ob Sie eine Frage zum Produkt haben, eine Partnerschaft erkunden möchten oder einfach nur Hallo sagen wollen — schreiben Sie uns. Wir lesen jede Nachricht.
Get in touch
Questions, feedback, or partnership ideas — we'd love to hear from you.